ALMACENES DE DATOS: IMPORTANCIA DE LA ESTANDARIZACION DE LAS DIRECCIONES PARA LAS EMPRESAS DE HOY EN DIA
Autora: Lic. Liudmila Padrón Torres
Empresa: Empresa de Telecomunicaciones de Cuba S.A (ETECSA V.C.)
e/mail: lumy@vcl.etecsa.cu
Fecha de realización del trabajo: 01/01/2006
PALABRAS CLAVES: almacén de datos, data warehouse, limpieza de datos, estandarización de direcciones.
RESUMEN
Los almacenes de datos son el centro de atención para las grandes empresas de hoy en día, ya que constituyen uno de los soportes fundamentales para el proceso de toma de decisiones gerenciales; de ahí la importancia de que la información guardada en ellos sea confiable y con calidad. Uno de los procesos en la construcción de estos y que contribuye a lograr este objetivo es la limpieza de datos, y junto con ella la estandarización de direcciones. Para comunicarse efectivamente con sus clientes, por teléfono o por correo, una empresa debe mantener una lista de sus clientes extraordinariamente limpia y con sus direcciones normalizadas. Esto evita problemas como el de la pérdida de credibilidad o de imagen de la organización, al hacer envíos precisos y al brindarle al cliente un servicio más rápido y profesional.
INTRODUCCION
Desde un inicio, las bases de datos se convirtieron en una herramienta fundamental de control y manejo de las operaciones comerciales. Fue así como en unos pocos años en grandes empresas y negocios existía un considerable número de información almacenada en diferentes fuentes de datos y estas ya habían alcanzado un tamaño considerablemente grande.
Con esta gran acumulación de información, los directivos de tales empresas y negocios se dieron cuenta que esta podría tener un fin útil, al estar reflejada la mayoría de sus operaciones comerciales durante los llamados ciclos de negocios propios del mercado.
A su vez, los mercados empresariales han experimentado una transformación radical. Las empresas demandan mayor rapidez y eficiencia en la entrega de productos, y mejora en todos los servicios existentes, por lo que se hace imprescindible encontrar formas más eficaces de distribuir los productos, más facilidades para hacer estudios de mercado basados en la información de las operaciones comerciales de las empresas y de sus clientes y, en definitiva, mayor rapidez a la hora de tomar decisiones.
Por tanto, pensaron en lo ideal que sería unificar las diferentes fuentes de información de las cuales disponían, en un único lugar, al que sólo se le incorporaría información relevante, sobre la base de una estructura organizada, integrada, lógica, dinámica y de fácil explotación. La respuesta a esto fueron los Almacenes de Datos o Data Warehouse (DW).
Sin embargo, para hacer un uso eficiente de la información histórica almacenada en un DW para la ayuda a la toma de decisiones, era vital garantizar que estos datos fueran fáciles de obtener, estandarizados y confiables.
Así y todo, el problema de la limpieza de datos es poco tratado o evitado por muchas empresas, al no considerar adecuadamente el impacto para el negocio de tener almacenada información deficiente.
ALMACENES DE DATOS. CONCEPTOS BASICOS
Un Almacén de Datos o Data Warehouse (DW) es un almacén de información temática orientado a cubrir las necesidades de aplicaciones de los sistemas de Soporte de Decisiones (DSS) y de la Información de Ejecutivos (EIS), que permite acceder a la información corporativa para la gestión, control y apoyo a la toma de decisiones.[4]
Dicha información es construida a partir de bases de datos que registran las transacciones de los negocios de las organizaciones (bases de datos operacionales), y su importancia reside en elementos como los siguientes:
• Contribuye a la toma de decisiones tácticas y estratégicas proporcionando un sentido automatizado para identificar información clave desde volúmenes de datos generados por procesos tradicionales o elementos de software.
• Posibilita medir las acciones y los resultados de una mejor forma.
• Los procesos empresariales pueden ser optimizados. El tiempo perdido esperando por información que finalmente es incorrecta o no encontrada, es eliminada.
• Permite a los usuarios dar prioridad a decisiones y acciones, por ejemplo, a qué segmentos de clientes deben ir dirigidas las siguientes acciones de marketing.
En general un DW es un conjunto de datos con las siguientes características:
• Temático
Los datos están almacenados por materias o temas (clientes, campañas, productos). Estos se organizan desde la perspectiva del usuario final, mientras que en las Bases de Datos operacionales se organizan desde la perspectiva de la aplicación, con vistas a lograr una mayor eficiencia en el acceso a los datos
• Integrado
Todos los datos almacenados en el DW están integrados. Las bases de datos operacionales orientadas hacia las aplicaciones fueron creadas sin pensar en su integración, por lo que un mismo tipo de datos puede ser expresado de diferente forma en dos bases de datos operacionales distintas (Por ejemplo, para representar el sexo: ‘Femenino’ y ‘Masculino’ o ‘F’ y ‘M’).
• No volátil
Únicamente hay dos tipos de operaciones en el DW: la carga de los datos procedentes de los entornos operacionales (carga inicial y carga periódica) y la consulta de los mismos. La actualización de datos no forma parte de la operativa normal de un DW.
• Histórico
El tiempo debe estar presente en todos los registros contenidos en un DW. Las bases de datos operacionales contienen los valores actuales de los datos, mientras que los DW contienen información actual y resúmenes de esta en el tiempo.
ARQUITECTURA
Los bloques funcionales que se corresponden con un sistema de información completo que utiliza un DW se muestran gráficamente en la Figura 1.
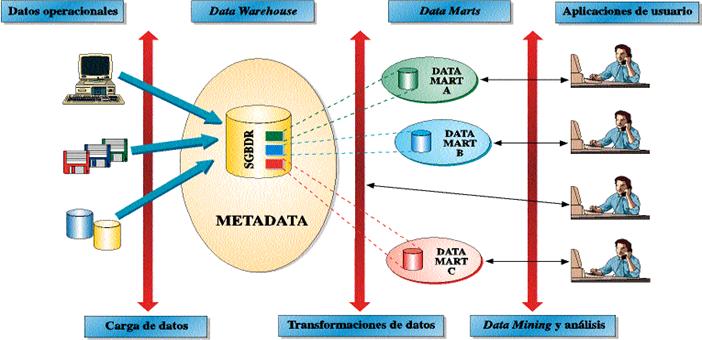
Figura 1: Arquitectura de un Data Warehouse [4]
• Nivel operacional
Contiene datos primitivos (operacionales) que están siendo permanentemente actualizados, usados por los sistemas operacionales tradicionales que realizan operaciones transaccionales.
• Almacén de datos o DW
Contiene datos primitivos correspondientes a sucesivas cargas del DW y algunos datos derivados. Los datos derivados son datos generados a partir de los datos primitivos al aplicarles algún tipo de procesamiento (resúmenes).
• Nivel departamental (Data Mart)
Contiene casi exclusivamente datos derivados. Cada departamento de la empresa determina su nivel departamental con información de interés a dicho nivel. Va a ser el blanco de salida sobre el cual los datos en el almacén son organizados y almacenados para las consultas directas por los usuarios finales, los desarrolladores de reportes y otras aplicaciones.
• Nivel individual
Contiene pocos datos, resultado de aplicar heurísticas, procesos estadísticos, etc., a los datos contenidos en el nivel anterior. El nivel individual es el objetivo final de un DW. Desde este nivel accederá el usuario final y se podrán plantear diferentes hipótesis, así como navegar a través de los datos contenidos en el DW.
PROCESOS
Existen un conjunto básico de procesos detrás de una arquitectura de un DW de suma importancia para el mismo.
Primeramente se realiza el proceso de extracción, que consiste en estudiar y entender los datos fuente, tomando aquellos que son de utilidad para el almacén. Una vez que los datos son extraídos, éstos se transforman a una forma presentable y de valor para los usuarios. Este proceso incluye corrección de errores, resolución de problemas de dominio, borrado de campos que no son de interés, generación de claves, agregación de información, etc.
Al terminar el proceso de transformación, se hace la carga de los datos en el DW y seguido se realizan controles de calidad para asegurar que la misma sea correcta. Cuando la información se encuentra disponible, se le informa al usuario. Es importante publicar todos los cambios que se hayan realizado. En este momento ya el usuario final puede realizar consultas. Este debe disponer de herramientas de consulta y procesamiento de datos.
A veces es aconsejable seguir el camino inverso de carga. Por ejemplo, pueden alimentarse los sistemas con información depurada del DW o almacenar en el mismo alguna consulta generada por el usuario que sea de interés, por eso se realiza la retroalimentación de datos o feedback.
También se realiza el proceso de auditoría, que permite conocer de dónde proviene la información así como qué cálculos la generaron.
Ya construido el DW, es de interés para la empresa que llegue la información a la mayor cantidad de usuarios pero, por otro lado, se tiene sumo cuidado de protegerla contra posibles 'hackers', 'snoopers' o espías (seguridad).
Además, se deben realizar actividades de backup y restauración de la información, tanto de la almacenada en el DW como de la que circula desde los sistemas fuente al almacén.
LIMPIEZA DE DATOS
Generalmente las empresas no cuentan con aplicaciones únicas para cada parte de la operativa del negocio, sino que pueden tener replicaciones y distintos sistemas para atender un mismo conjunto de operaciones, y en esos casos es probable que las bases de datos de los sistemas operacionales contengan datos duplicados, a veces erróneos, superfluos o incompletos. A esto se le suman los posibles errores a la hora de la entrada de datos a los sistemas de datos operacionales. Estas, y otras mostradas en la Figura 2, son algunas de las cuestiones que contribuyen a la suciedad de los datos.

Figura 2: Algunos errores que provocan suciedad en los datos
La limpieza de datos se encuentra dentro del proceso de transformación de datos. Esta, es mucho más que simplemente actualizar registros con datos buenos. Una limpieza de datos seria, involucra descomposición y reensamblaje de datos. La limpieza de datos se puede dividir en seis pasos: separar en elementos, estandarizar, verificar, machear, agrupar y documentar. [3]
Por ejemplo, si tenemos direcciones de clientes las cuales queremos limpiar, lo primero sería separar este campo en los elementos principales de la dirección (Calle, No., Entre Calles, Código Postal, etc.). Lo segundo sería estandarizar los elementos, o sea lograr que estos queden de forma normalizada. Luego se verificaría si los elementos estandarizados contienen errores en su contenido, y ya estaríamos listos para machear (hacer parejas o correspondencias) y agrupar, que consiste en reconocer que algunas de las partes de la dirección constituyen una agrupación, por ejemplo, si se tienen dos direcciones iguales de diferentes clientes que están relacionados de alguna forma (son hermanos o están casados), estos forman un grupo. Por último se documentarían los resultados de los pasos anteriores en metadatos. Esto ayuda a que las siguientes limpiezas sean más capaces de reconocer direcciones y a que los usuarios finales de las aplicaciones puedan llevar a cabo mejor las operaciones de un DW.
Como se puede apreciar, sería bastante tedioso llevar manualmente este proceso, y para hacerlo automatizado se necesitaría de aplicaciones sofisticadas que contengan algoritmos de análisis gramatical (parsing) de direcciones, algoritmos de macheo, e inmensas tablas con gran cantidad de entradas que provea sinónimos para las diferentes partes de las direcciones.
En algunos casos es posible crear programas de limpieza efectivos. Pero en el caso de bases de datos grandes, imprecisas e inconsistentes, el uso de las herramientas comerciales, ya existentes, puede ser casi obligatorio.
¿QUE ES ESTANDARIZACION? IMPORTANCIA DE LA ESTANDARIZACION DE DIRECCIONES PARA LAS EMPRESAS DE HOY EN DIA
La estandarización forma parte de los seis pasos necesarios para llevar a cabo la limpieza de datos. Esta consiste en separar la información en diferentes campos, así como unificar ciertos criterios para un mejor manejo y manipulación de los datos.
Tener datos estandarizados, consistentes y con calidad, resulta muy útil y a veces de vital importancia para las empresas que utilizan almacenes de datos. Un ejemplo de ello son aquellas organizaciones cuyos datos referentes a sus clientes son de gran valor.
El manejo de los nombres y direcciones de los clientes no es tarea fácil. Más del 50% de las compañías en Internet no pueden responder a las necesidades de todos sus clientes y no se pueden relacionar con ellos a causa de la falta de calidad en sus datos. [2]
Para comunicarse efectivamente con sus clientes, por teléfono, por correo o por cualquier otra vía, una empresa debe mantener una lista de sus clientes extraordinariamente limpia. Esto no solo provoca que existan menos correos devueltos y más envíos precisos, sino que además, mejora la descripción y análisis de los clientes, que se traduce en un servicio más rápido y profesional.
Hay muchos ejemplos de aplicaciones basadas en la información del cliente que necesitan que sus datos, y principalmente sus direcciones tengan integridad, algunos de ellos son:
• Sistemas CRM (Customer Relationship Management, Gestión de las Relaciones con el Cliente)
• E-Business (Negocios electrónicos)
• Call Centers (Oficina o compañía centralizada que responde llamadas telefónicas de clientes o que hacen llamadas a clientes (telemarketing))
• Sistemas de Marketing
Del mismo modo, podemos mencionar algunas de las organizaciones que mayormente son beneficiadas por la limpieza de los datos de sus clientes.
• Bancos y Finanzas
• Gobierno
• Salud
• Telecomunicaciones
CONCLUSIONES
1. Los almacenes de datos son el centro de atención de las grandes empresas actuales, porque son una colección de datos donde se encuentra integrada la información de estas, proporcionando una herramienta para que puedan hacer un mejor uso de la información y para el soporte al proceso de toma de decisiones gerenciales.
2. Existen numerosas causas que provocan suciedad en los registros de los sistemas operacionales, lo que trae como consecuencia que haya gran cantidad de datos almacenados en las empresas que carece de la calidad adecuada para ser utilizada de forma confiable.
3. El problema de la limpieza de datos es uno de los tres problemas fundamentales de los DW. Sin embargo, es poco tratado o evitado por muchas organizaciones, ya que no consideran adecuadamente el impacto negativo que puede ocasionar para el negocio el tener almacenada información deficiente.
4. En algunos casos es posible crear programas de limpieza a la medida para la empresa en cuestión, pero en el caso de bases de datos con grandes números de registros puede ser casi obligatorio el uso de las herramientas comerciales ya existentes.
5. Para las organizaciones actuales, la estandarización de las direcciones de sus listas de clientes es un punto fundamental a tener en cuenta, ya que direcciones de un DW que no tengan esta característica pueden provocar pérdida de credibilidad de las organizaciones, que a su vez, lleva a la pérdida de clientes como consecuencia de un servicio poco eficaz.
BIBLIOGRAFIA
[1] Casares C. (Nov/2005) - Data Warehousing, http://www.programacion.com/bbdd/tutorial/warehouse/15/#warehousing_desarrollo_confi
[2] Hussain S.; Beg J. (Oct/2005). - Data Quality: A Problem and an Approach, http://doc.advisor.com/doc/13060
[3] Kimball R. (Oct/2005) -Dealing with Dirty Data, http://www.dbmsmag.com/9609d14.html
[4] Martín J.; Morrás C.; García M. L.; Tello L. I.;Vivancos A. J. (Oct/2005) - Sistemas de soporte a la gestión del negocio, http://www.tid.es/presencia/publicaciones/comsid/esp/articulos/vol812/soporte/soporte.html
[5] Torres H.; Visitación M.; Grau A.; Mar M.; Barranco H.; Soldado M. (Oct/2005). -Bases de datos y data warehouse: Herramientas estratégicas para la eficacia comercial, http://www-lsi.ugr.es/~rosana/ investigacion/bd_efsi04.pdf